Projects
ANTIFRAGILITY
ANTIFRAGILITY: Closed-loop Induced Antifragility of Dynamical Systems using Physics, Control Theory and ML

CALSIM
CALSIM: Computational Intelligence for Models Calibration in Agent-based Traffic Simulations

PHIML
PHIML: Combining Mechanistic Modelling, Control, and Neural Processing for Traffic Control

BIOPHYLEARN
BIOPHYLEARN: Fusing Biophysics and Machine Learning for Mathematical and Computational Oncology

BIOMECHS
BIOMECHS: Systems for Deep Reinforcement Learning Synthesis of Plausible Human Motion

PRECISION
PRECISION: Profile Extraction from Clinical Insights for Smart Individualized Oncology
Context

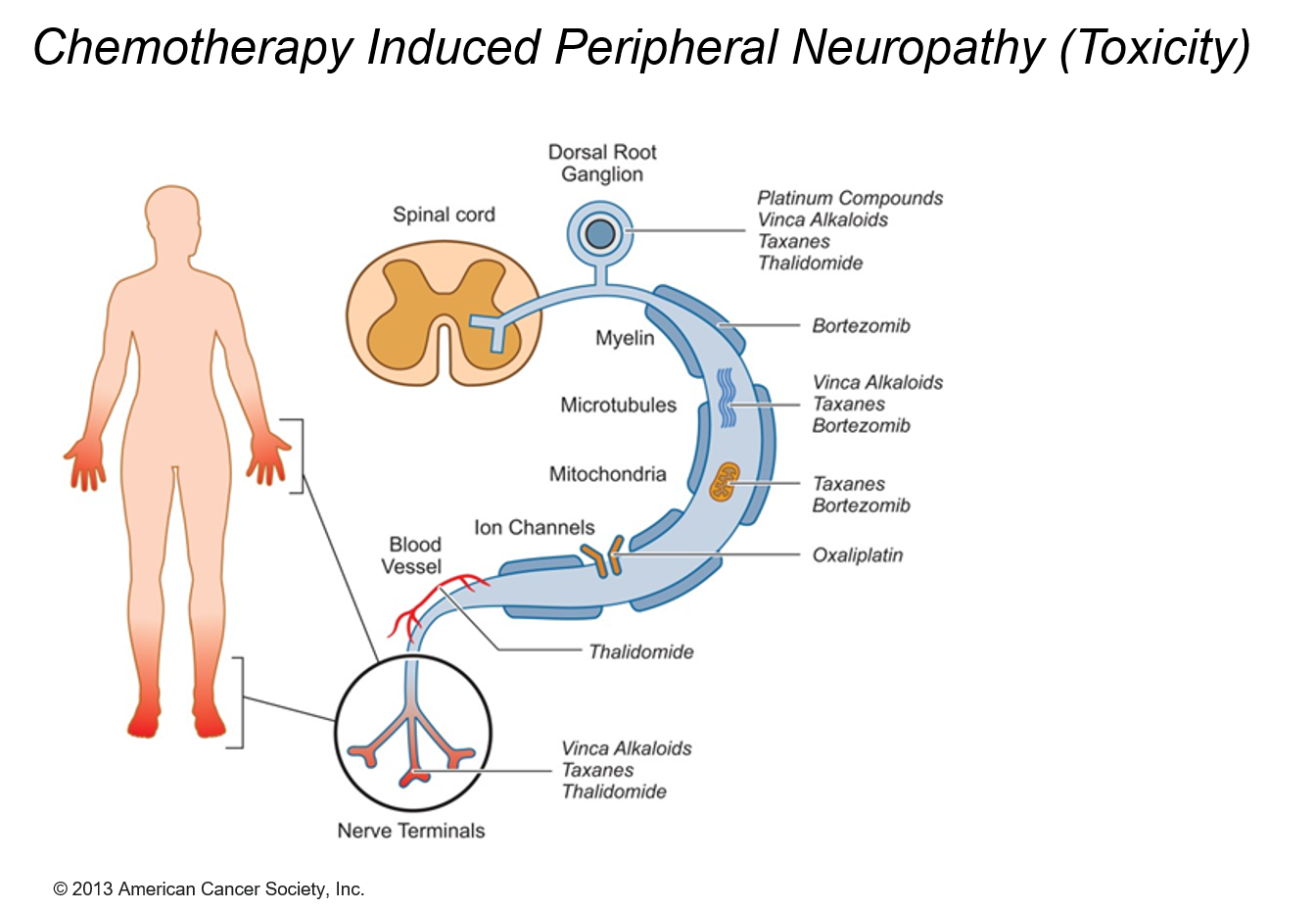
Over the past decades, early diagnosis, new drugs and more personalised treatment have led to impressive increases in survival rates of cancer patients. Yet, chemotherapy-induced peripheral neuropathy (CIPN), one of the most disabling side effects of commonly used chemotherapeutic drugs, is a severe problem in oncology leading to dose reduction, treatment delay or discontinuation. CIPN causes long-lasting disturbances of daily functioning and quality of life in a considerable proportion of patients. With an increasing number of cancer survivors, more attention is being paid to persistent sequelae of tumour treatment and supportive measures used as adjuncts to mainstream cancer care to control symptoms and enhance well-being.
CIPN describes the damage to the peripheral nervous system incurred by a patient who has received a chemotherapeutic agent that is known to be neurotoxic. Independent of the mechanisms of action, the targeted impact of such agents is on axonal transmission with consequences leading up to neuronal apoptosis.
Computational Oncology Approach
The incidence of peripheral neuropathy differs significantly across chemotherapeutic agents. The prevalence and severity of CIPN are dependent upon several factors relating to both drug pharmacokinetics (e.g., PK, cumulative dose and treatment duration) and pharmacodynamics (e.g., PD, mechanisms of toxicity and patient characteristics). Typically, in vitro and in vivo tests are performed to investigate drug toxicity. In comparison to such experimental approaches, computational methods, including machine learning and structural alerts, have shown great advantages since they are green, fast, cheap, accurate, and most importantly they could be done before the patient receive the therapy. Although such approaches exploit patient-specific risk factors that have been associated with the susceptibility for developing CIPN.
We are aware of no publicly available, validated in silico system to predict the development of CIPN in individual patients. The goal of this project is to develop a clinical decision-support system to predict CIPN development. Using simulation, mechanistic modelling, and machine learning we will develop and validate predictive models to quantify the risk of developing CIPN and deploy a standalone clinical decision-making system that will improve cancer treatment and survivorship care planning.

The project proposes a new digital intervention to support clinical oncologists in designing CIPN-aware cancer therapies. Understanding low-level tumor biology and patient genetics can provide unique insights that were previously impossible, to identify genetic predictors of CIPN. Correlating such information with models of tumor growth and patient’s clinical peculiarities, the system can isolate the most relevant cancer response patterns to adjust therapy parameters. The overall goal of the project is to fuse the insights gained at each of these levels in order to build a decision support system that predicts the development of CIPN in a particular patient. The system will learn the governing drug PK/PD differential equations directly from patient data by combining key pharmacological principles with neural ordinary differential equations refined through simulations for improved temporal prediction metrics. Furthermore, by incorporating key PK/PD concepts into its architecture, the system can generalize and enable the simulations of patient responses to untested dosing regimens. These emphasize the potential such a system holds for automated predictive analytics of patient drug response. The end result of the project will be a simple app that will collect physician inputted patient clinical parameters and eventually health records and will provide, given the therapy drug choice a prediction of the severity of CIPN before the chemotherapy regimen. Additionally, the physician and patient will get interpretable insights and a clear explanation of how each of the factors affects the prognosis. The entire processing and data aggregation and learning will happen in the cloud using GDPR-aware data handling.

The project is based on large-scale data fusion that provides a multi-faceted profile of the patient, drugs, tumor and how they interact. This will finally support personalized intervention and adaptive therapies that maximise efficacy and minimize toxicity.

COMPONENS
COMPutational ONcology ENgineered Solutions
Introduction
COMPONENS focuses on the research and development of tools, models and infrastructure needed to interpret large amounts of clinical data and enhance cancer treatments and our understanding of the disease. To this end, COMPONENS serves as a bridge between the data, the engineer, and the clinician in oncological practice.
Thus, knowledge-based predictive mathematical modelling is used to fill gaps in sparse data; assist and train machine learning algorithms; provide measurable interpretations of complex and heterogeneous clinical data sets, and make patient-tailored predictions of cancer progression and response.GLUECK: Growth pattern Learning for Unsupervised Extraction of Cancer Kinetics
Neoplastic processes are described by complex and heterogeneous dynamics. The interaction of neoplastic cells with their environment describes tumor growth and is critical for the initiation of cancer invasion. Despite the large spectrum of tumor growth models, there is no clear guidance on how to choose the most appropriate model for a particular cancer and how this will impact its subsequent use in therapy planning. Such models need parametrization that is dependent on tumor biology and hardly generalize to other tumor types and their variability. Moreover, the datasets are small in size due to the limited or expensive measurement methods. Alleviating the limitations that incomplete biological descriptions, the diversity of tumor types, and the small size of the data bring to mechanistic models, we introduce Growth pattern Learning for Unsupervised Extraction of Cancer Kinetics (GLUECK) a novel, data-driven model based on a neural network capable of unsupervised learning of cancer growth curves. Employing mechanisms of competition, cooperation, and correlation in neural networks, GLUECK learns the temporal evolution of the input data along with the underlying distribution of the input space. We demonstrate the superior accuracy of GLUECK, against four typically used tumor growth models, in extracting growth curves from a set of four clinical tumor datasets. Our experiments show that, without any modification, GLUECK can learn the underlying growth curves being versatile between and within tumor types.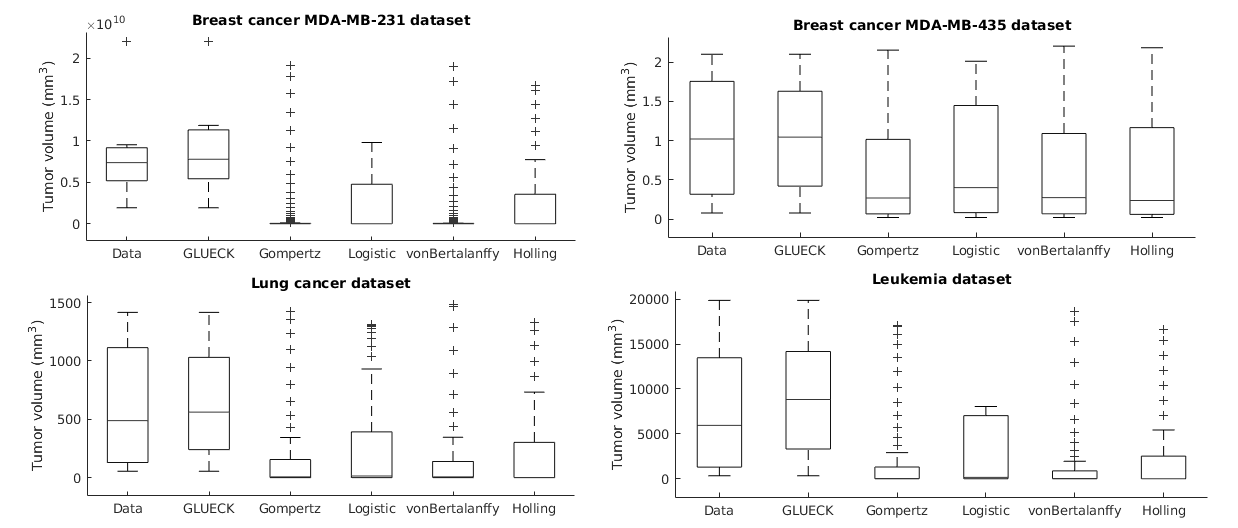
Preprint https://www.biorxiv.org/content/10.1101/2020.06.13.140715v1 Code https://gitlab.com/akii-microlab/ecml-2020-glueck-codebase
PRINCESS: Prediction of Individual Breast Cancer Evolution to Surgical Size
Modelling surgical size is not inherently meant to replicate the tumor's exact form and proportions, but instead to elucidate the degree of the tissue volume that may be surgically removed in terms of improving patient survival and minimize the risk that a second or third operation will be needed to eliminate all malignant cells entirely. Given the broad range of models of tumor growth, there is no specific rule of thumb about how to select the most suitable model for a particular breast cancer type and whether that would influence its subsequent application in surgery planning. Typically, these models require tumor biology-dependent parametrization, which hardly generalizes to cope with tumor heterogeneity. In addition, the datasets are limited in size owing to the restricted or expensive methods of measurement. We address the shortcomings that incomplete biological specifications, the variety of tumor types and the limited size of the data bring to existing mechanistic tumor growth models and introduce a Machine Learning model for the PRediction of INdividual breast Cancer Evolution to Surgical Size (PRINCESS). This is a data-driven model based on neural networks capable of unsupervised learning of cancer growth curves. PRINCESS learns the temporal evolution of the tumor along with the underlying distribution of the measurement space. We demonstrate the superior accuracy of PRINCESS, against four typically used tumor growth models, in extracting tumor growth curves from a set of nine clinical breast cancer datasets. Our experiments show that, without any modification, PRINCESS can learn the underlying growth curves being versatile between breast cancer types.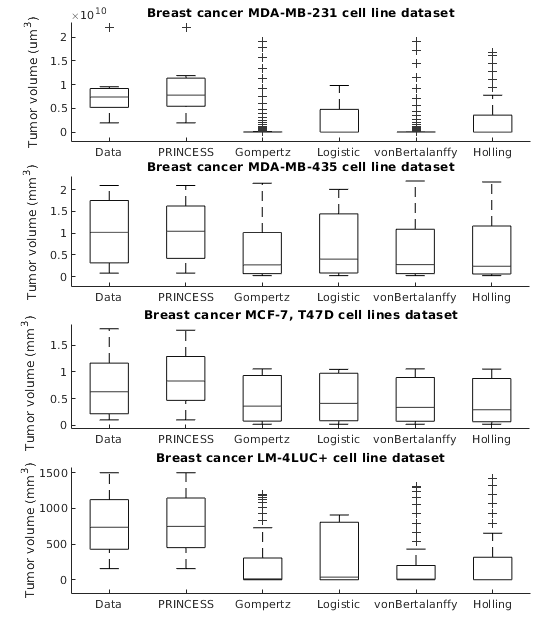
Preprint https://www.biorxiv.org/content/10.1101/2020.06.13.150136v1 Code https://gitlab.com/akii-microlab/cbms2020
TUCANN: TUmor Characterization using Artificial Neural Networks
Despite the variety of imaging, genetic and histopathological data used to assess tumors, there is still an unmet need for patient-specific tumor growth profile extraction and tumor volume prediction, for use in surgery planning. Models of tumor growth predict tumor size based on measurements made in histological images of individual patients’ tumors compared to diagnostic imaging. Typically, such models require tumor biology-dependent parametrization, which hardly generalizes to cope with tumor variability among patients. In addition, the histopathology specimens datasets are limited in size, owing to the restricted or single-time measurements. In this work, we address the shortcomings that incomplete biological specifications, the inter-patient variability of tumors, and the limited size of the data bring to mechanistic tumor growth models and introduce a machine learning model capable of characterizing a tumor, namely its growth pattern, phenotypical transitions, and volume. The model learns without supervision, from different types of breast cancer data the underlying mathematical relations describing tumor growth curves more accurate than three state-of-the-art models on three publicly available clinical breast cancer datasets, being versatile among breast cancer types. Moreover, the model can also, without modification, learn the mathematical relations among, for instance, histopathological and morphological parameters of the tumor and together with the growth curve capture the (phenotypical) growth transitions of the tumor from a small amount of data. Finally, given the tumor growth curve and its transitions, our model can learn the relation among tumor proliferation-to-apoptosis ratio, tumor radius, and tumor nutrient diffusion length to estimate tumor volume, which can be readily incorporated within current clinical practice, for surgery planning. We demonstrate the broad capabilities of our model through a series of experiments on publicly available clinical datasets.
Preprint https://www.biorxiv.org/content/10.1101/2020.06.08.140723v1 Code https://gitlab.com/akii-microlab/icann-2020-bio
CHIMERA: Combining Mechanistic Models and Machine Learning for Personalized Chemotherapy and Surgery Sequencing in Breast Cancer
Mathematical and computational oncology has increased the pace of cancer research towards the advancement of personalized therapy. Serving the pressing need to exploit the large amounts of currently underutilized data, such approaches bring a significant clinical advantage in tailoring the therapy. CHIMERA is a novel system that combines mechanistic modelling and machine learning for personalized chemotherapy and surgery sequencing in breast cancer. It optimizes decision-making in personalized breast cancer therapy by connecting tumor growth behaviour and chemotherapy effects through predictive modelling and learning. We demonstrate the capabilities of CHIMERA in learning simultaneously the tumor growth patterns, across several types of breast cancer, and the pharmacokinetics of a typical breast cancer chemotoxic drug. The learnt functions are subsequently used to predict how to sequence the intervention. We demonstrate the versatility of CHIMERA in learning from tumor growth and pharmacokinetics data to provide robust predictions under two, typically used, chemotherapy protocol hypotheses.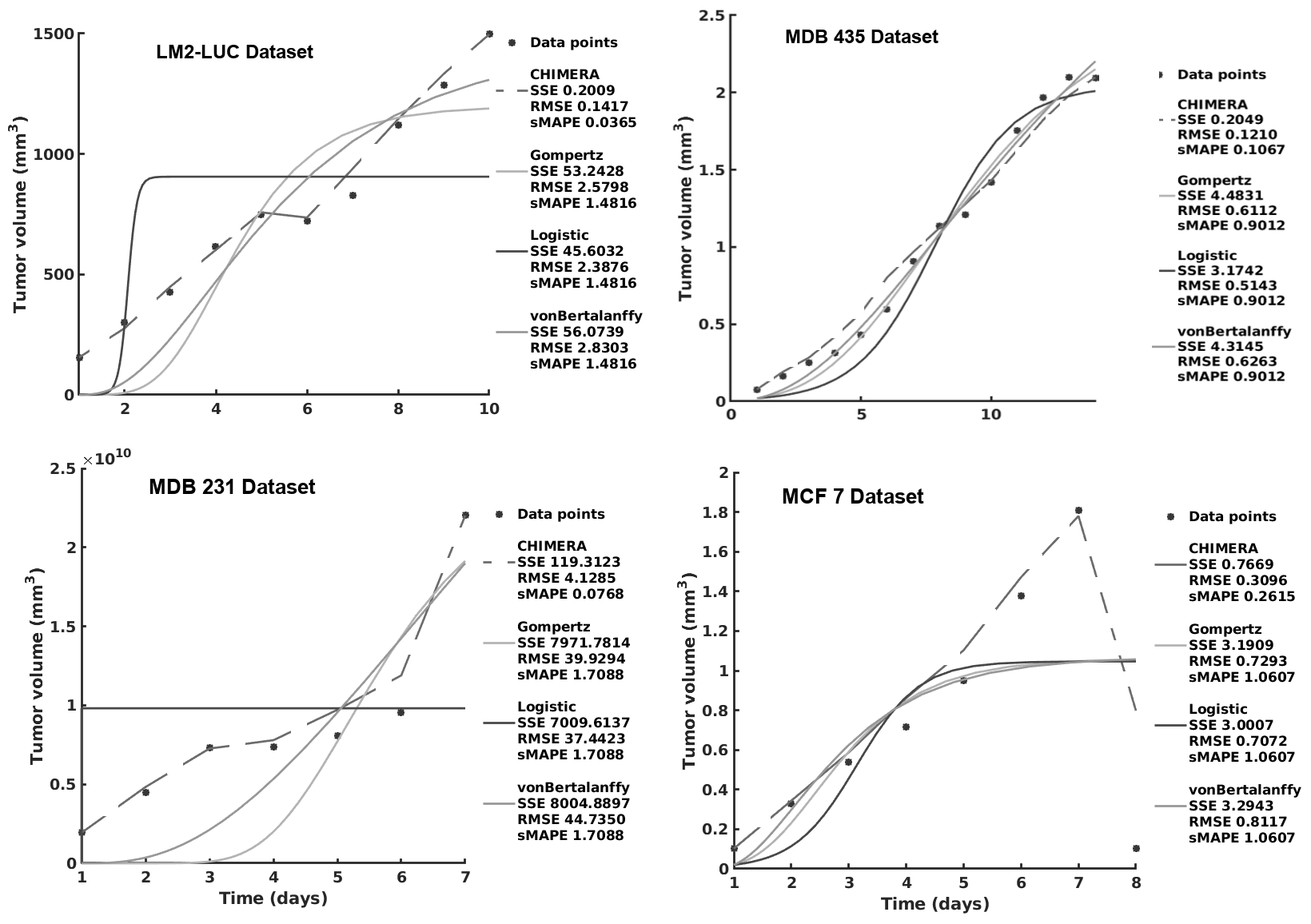
Preprint https://www.biorxiv.org/content/10.1101/2020.06.08.140756v1 Code https://gitlab.com/akii-microlab/bibe2020
PROMISE
Personalized Rehabilitation in Oncology specific Motor deficits using Intelligent Sensing and Extended reality
Context
Chemotherapy-induced neuropathies (CIPN) have gained clinical significance due to the prevalence of malignant disease and the use of new chemotherapeutic drugs; their prevalence is also reported to be 30%–40%, with high variance depending on the drug(s) used and treatment scheme. With over 600.000 new cases in 2018 and almost 2 million prevalent cases on a 5-year prediction in Germany, cancer is still in the foreground of chronic diseases that require innovative and impactful solutions. CIPN is one of the most frequent adverse effects of many commonly used chemotherapeutic agents and has a strong impact on patients' quality of life. CIPN is a severe problem in oncology leading to dose reduction, treatment delay, or discontinuation. It causes long-lasting disturbances of daily functioning and quality of life in a considerable proportion of patients, due to its sensory and motor symptoms.Research partners

Goal
PROMISE is a technological intervention for polyneuropathies that provides personalized quantification and adaptive compensation of sensorimotor deficits. The initial instantiation tackles CIPN and its rehabilitation in cancer survivors after chemotherapy. It proves the potential that motion capturing technologies, wearables, and machine learning algorithms have in combination in a digital intervention aiming at personalized physical rehabilitation.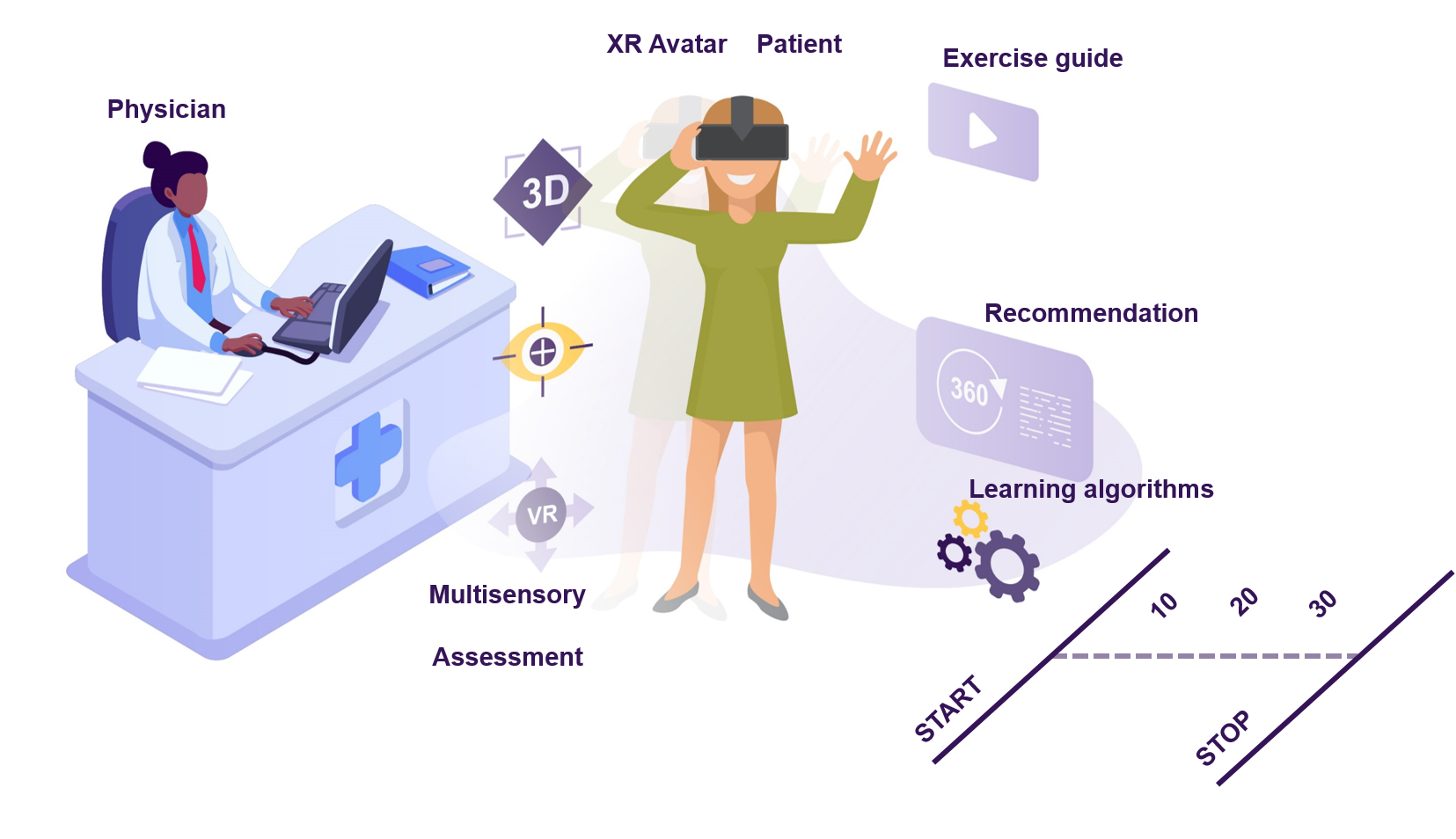
PROMISE explores the potential that digital interventions have for sensorimotor CIPN assessment and rehabilitation in cancer patients. Our primary goal is to demonstrate the benefits and impact that Extended Reality (XR) avatars and AI algorithms have in combination in a digital intervention aiming at 1) assessing the complete kinematics of deficits through learning underlying patient sensorimotor parameters, and 2) parametrize a multimodal XR stimulation to drive personalized deficit compensation in rehabilitation 3) quantitatively track the patient’s progress and automatically generate personalized recommendations 4) quantitatively evaluate and benchmark the effectiveness of the administered therapies.
Overview
The generic system architecture is depicted in the following diagram. The rich sensory data is responsible to describe a complete assessment. Through machine learning algorithms each of the modules provides a powerful interface from the patient to the physician.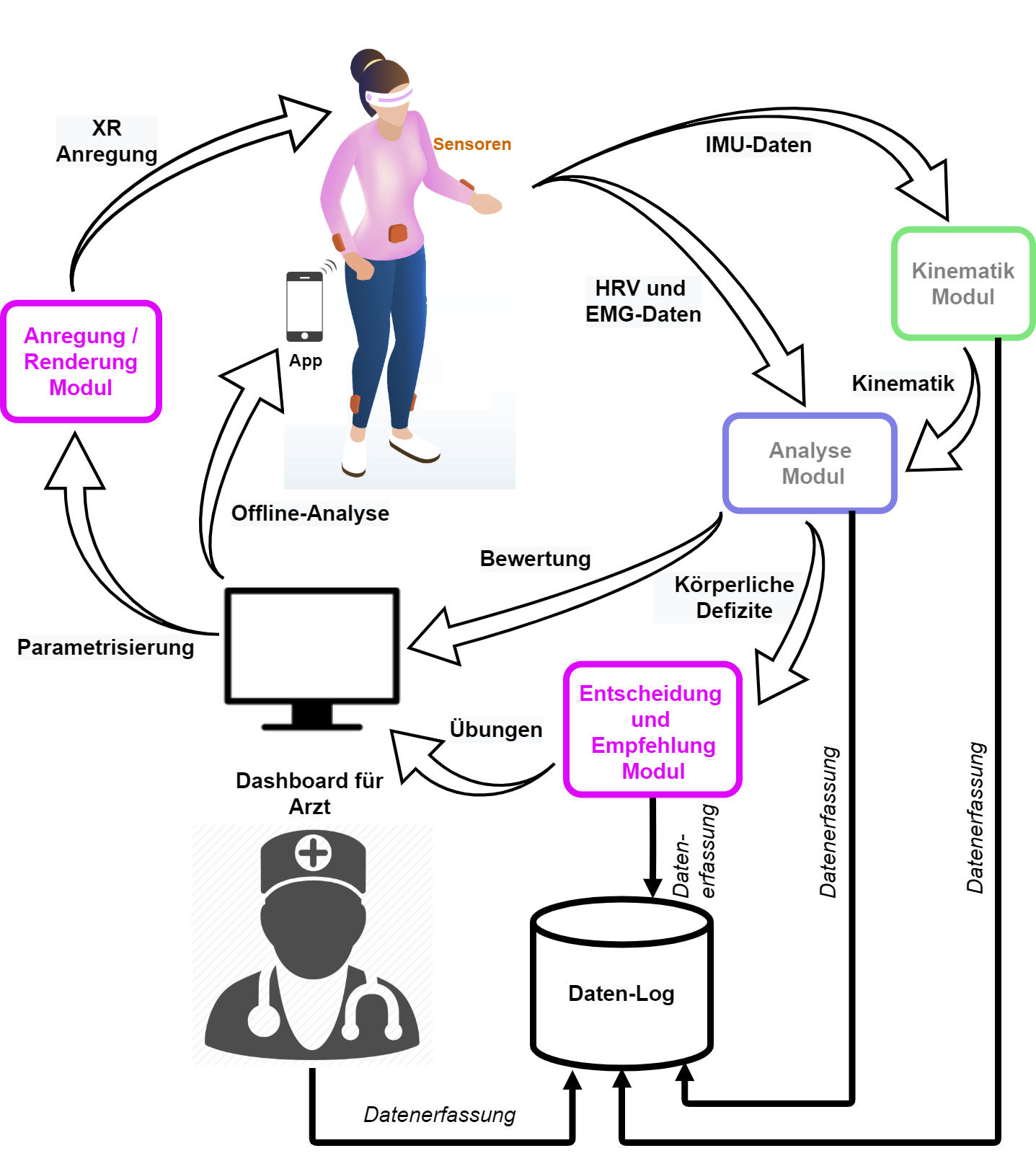
PROMISE will address the sensorimotor symptoms of CIPN. It will use commodity digital technologies, such as Extended Reality (XR) and Machine Learning (ML), in combination, for personalized CIPN sensorimotor rehabilitation. We expect that PROMISE will reduce the severity of the weakened or absent reflexes or the loss of balance control through personalized quantification of deficits and optimal compensation. All these with an affordable, adaptive, and accessible platform for both clinical and home-based rehabilitation. The core element is the inference system capable of translating the assessment into actionable insights and recommendations for the patient in both clinical and home-based rehabilitation deployment of PROMISE.
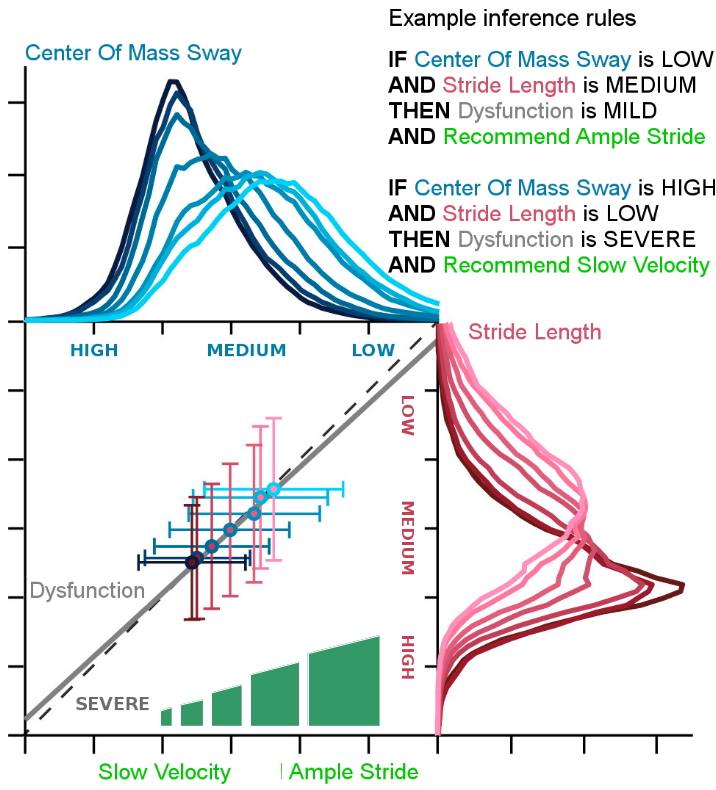
As a technical innovation, PROMISE will offer a platform that can be used in both clinical (laboratory) and home rehabilitation. PROMISE will use a combination of affordable wearables (i.e. IMU, EMG, HR) and recommend the best configuration of number and placement of such sensors that capture patient motion peculiarities.

For instance, the laboratory version will comprise the base platform and additionally all sensors and physician dashboards (i.e. cameras, IMUs, wearables, VR trackers) for a high-accuracy assessment and stimulation. The simulation plays an important role in the clinical version as the physician/therapist can guide the patient. The home-based rehabilitation version of the solution will use a limited set of sensors (i.e. IMUs) and focus continuous monitoring with limited / no stimulation. Such a modular design will allow PROMISE to cover the whole rehabilitation spectrum allowing for continuous patient interaction.
PERSEUS
Platform for Enhanced virtual Reality in Sport Exercise Understanding and Simulation

The PERSEUS (Platform for Enhanced virtual Reality in Sport Exercise Understanding and Simulation) is funded by the Central Innovation Programme for small and medium-sized enterprises (SMEs) (ZIM - Zentrales Innovationsprogramm Mittelstand) from the Federal Ministry for Economic Affairs and Energy.
Consortium

Goal
To support performance, elite athletes, such as goalkeepers, require a combination of general visual skills (e.g. visual acuity, contrast sensitivity, depth perception) and performance-relevant perceptual-cognitive skills (e.g. anticipation, decision-making). While these skills are typically developed as a consequence of regular, on-field practice, training techniques are available that can enhance those skills outside of, or in conjunction with, regular training. Perceptual training has commonly included sports vision training (SVT) that uses generic stimuli (e.g. shapes, patterns) optometry-based tasks with the aim of developing visual skills, or perceptual-cognitive training (PCT), that traditionally uses sport-specific film or images to develop perceptual-cognitive skills. Improvements in technology have also led to the development of additional tools (e.g. reaction time trainers, computer-based vision training, and VR systems) which have the potential to enhance perceptual skill using a variety of different equipment in on- and off-field settings that don’t necessarily fit into these existing categories. In this context we hypothesize that using high-fidelity VR systems to display realistic 3D sport environments could provide a mean to control anxiety, allowing resilience-training systems to prepare athletes for real-world, high-pressure situations and hence to offer a tool for sport psychology training. Moreover, a VE should provide a realistic rendering of the sports scene to achieve good perceptual fidelity. More important for a sport-themed VE is high functional fidelity, which requires an accurate physics model of a complex environment, real time response, and a natural user interface. This is of course complemented by precise body motion tracking and kinematic model extraction. The goal is to provide multiple scenarios to players at different levels of difficulty, providing them with improved skills that can be applied directly to the real sports arena, contributing to a full biomechanical training in VR. The project proposes the development of an AI powered VR system for sport psychological (cognitive) and biomechanical training. By exploiting neuroscientific knowledge in sensorimotor processing, Artificial Intelligence algorithms and VR avatar reconstruction, our lab along with the other consortium partners target the development of an adaptive, affordable, and flexible novel solution for goalkeeper training in VR.Overview
The generic system architecture is depicted in the following diagram.
Using time sequenced data one can extract the motion components from goalkeeper's motion and generate a VR avatar.
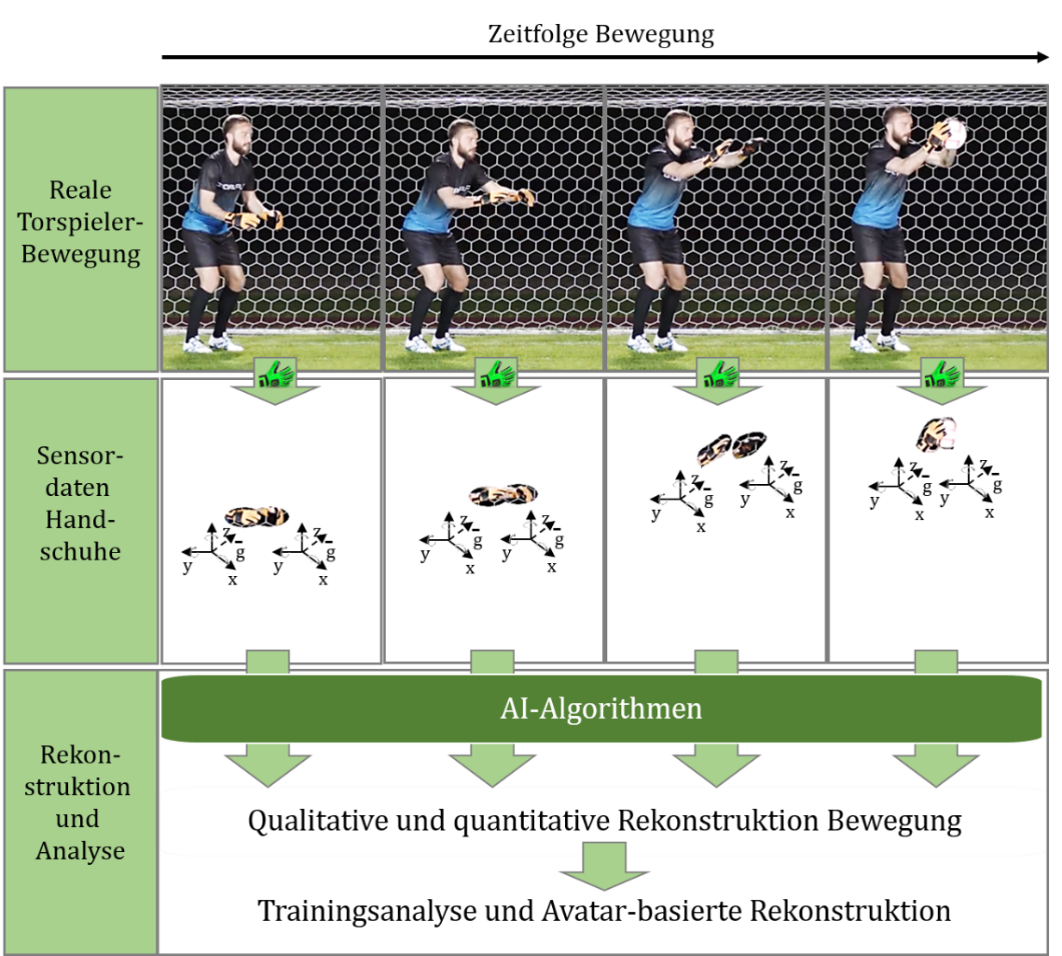
An initial view of the avatar compatibility with the real-world motion of the athlete is described in the next diagram.

The validation is done against ground truth data from a camera, whereas the data from the gloves are used to train the avatar kinematics and reconstruction. The gloves system is a lightweight embedded sensing system.
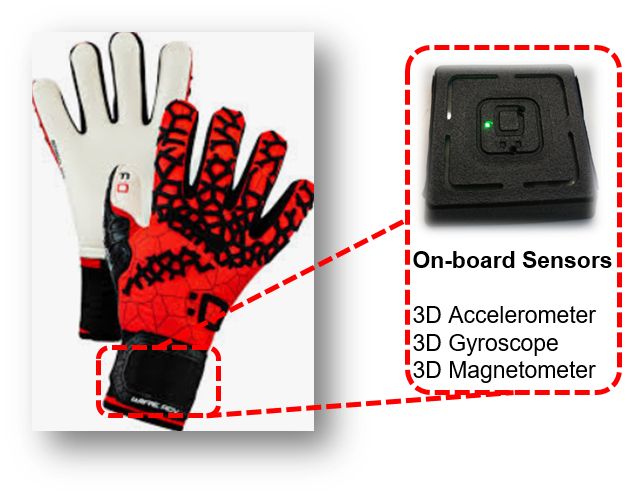
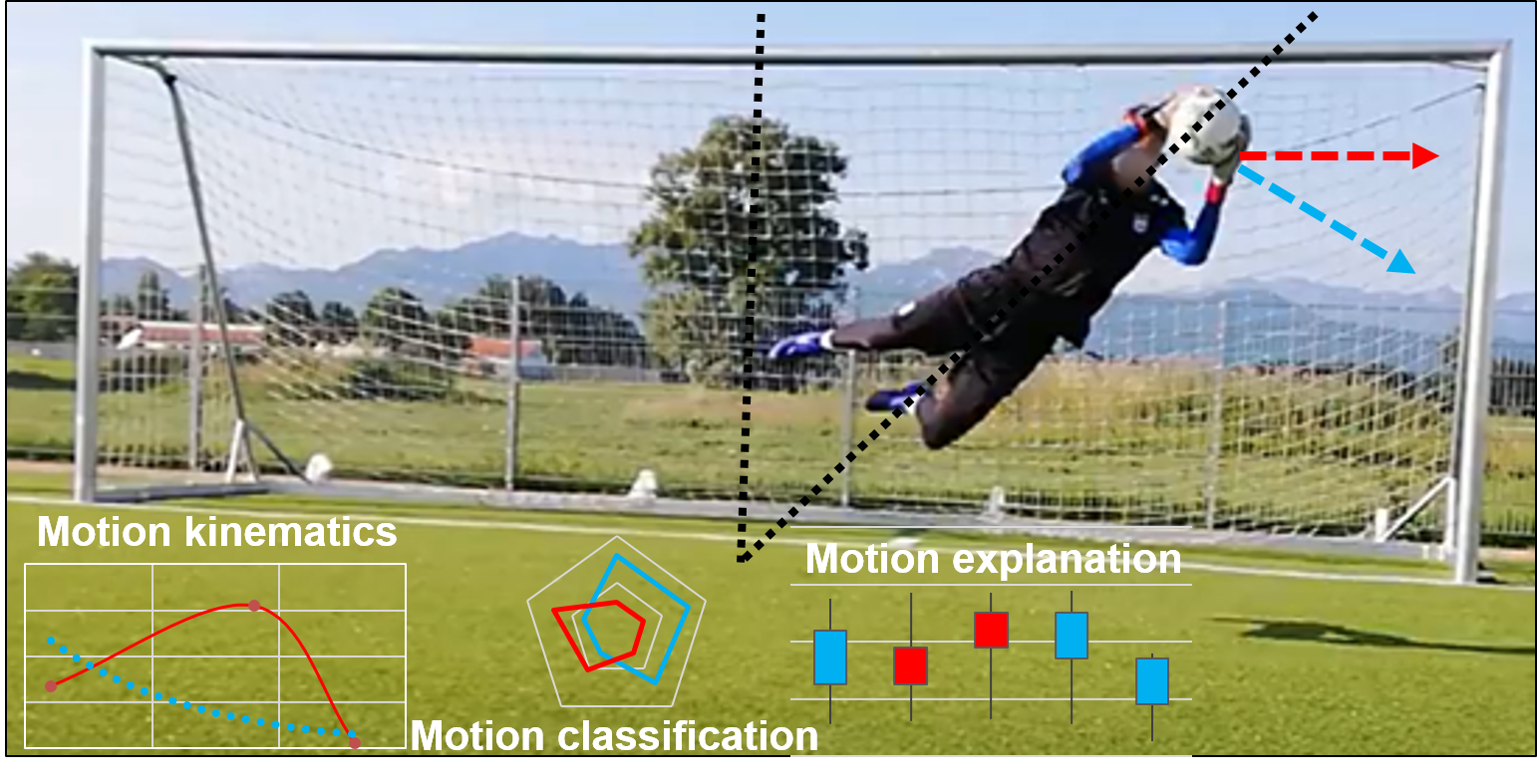
In the current study, we focus on extracting such goalkeeper analytics from kinematics using machine learning. We demonstrate that information from a single motion sensor can be successfully used for accurate and explainable goalkeeper kinematics assessment.
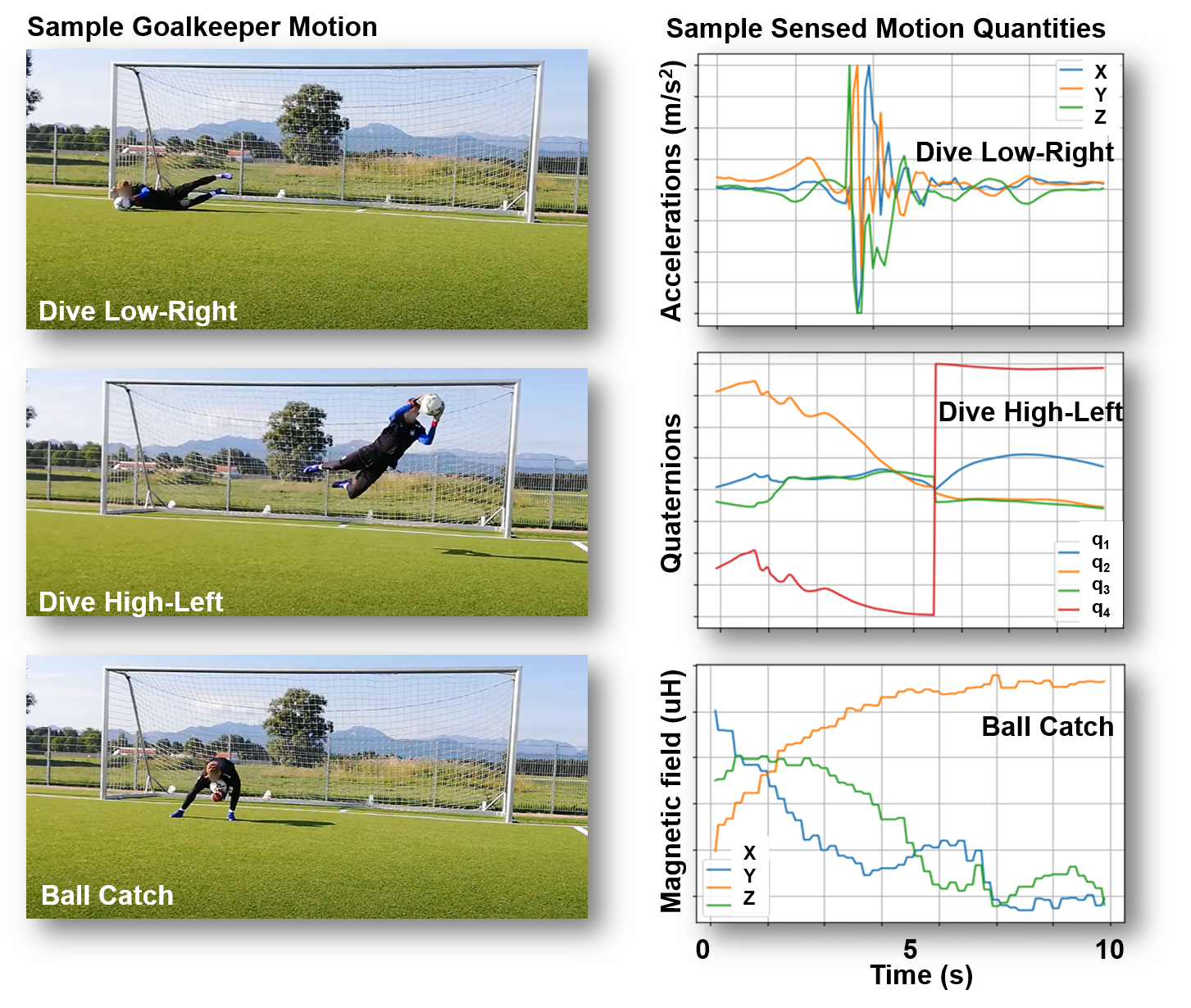
In order to exploit the richness and unique parameters of the goalkeeper's motion, we employ a robust machine learning algorithm that is able to discriminate dives from other types of specific motions directly from raw sensory data. Each prediction is accompanied by an explanation of how each sensed motion component contributes to describing a specific goalkeeper's action.
ENVISAS
Event-based Neuromorphic VISion for ASsistive Devices
Context
According to a study from the year 2010, about 39 million people are blind. These people are not able to perceive depth. To help this population to perceive their surroundings better, assistive medical devices were designed. With modern technologies and computing power, better solutions could be provided. If a medical device can provide a depth representation of the surrounding world in form of a depth map, this map can be used to transform the depth data into a multisensory (i.e audio, haptic) representation of the depth.Goal
Event cameras use bio-inspired sensors that differ from conventional frame-based camera sensors: instead of capturing images at a fixed rate, they asynchronously measure per-pixel brightness changes and output a stream of events that encode the time, location, and polarity (i.e. on/off) of the brightness changes. Novel methods are required to process the unconventional output of these sensors in order to unlock their potential. Depth estimation with a single event-based camera is a significantly different problem because the temporal correlation between events across multiple image planes cannot be exploited. Typical methods recover a semi-dense 3D reconstruction of the scene (i.e., 3D edge map) by integrating information from the events of a moving camera over time, and therefore require knowledge of camera motion. Recently, learning-based approaches have been applied to event-based data, thus unlocking their potential and making significant progress in a variety of tasks, such as monocular depth prediction. This way, one can benefit from an efficient visual perception of the scene for fast extraction of depth in assistive devices.Current stage
Toolset and Benchmark Framework for Monocular Event-based Depth Extraction
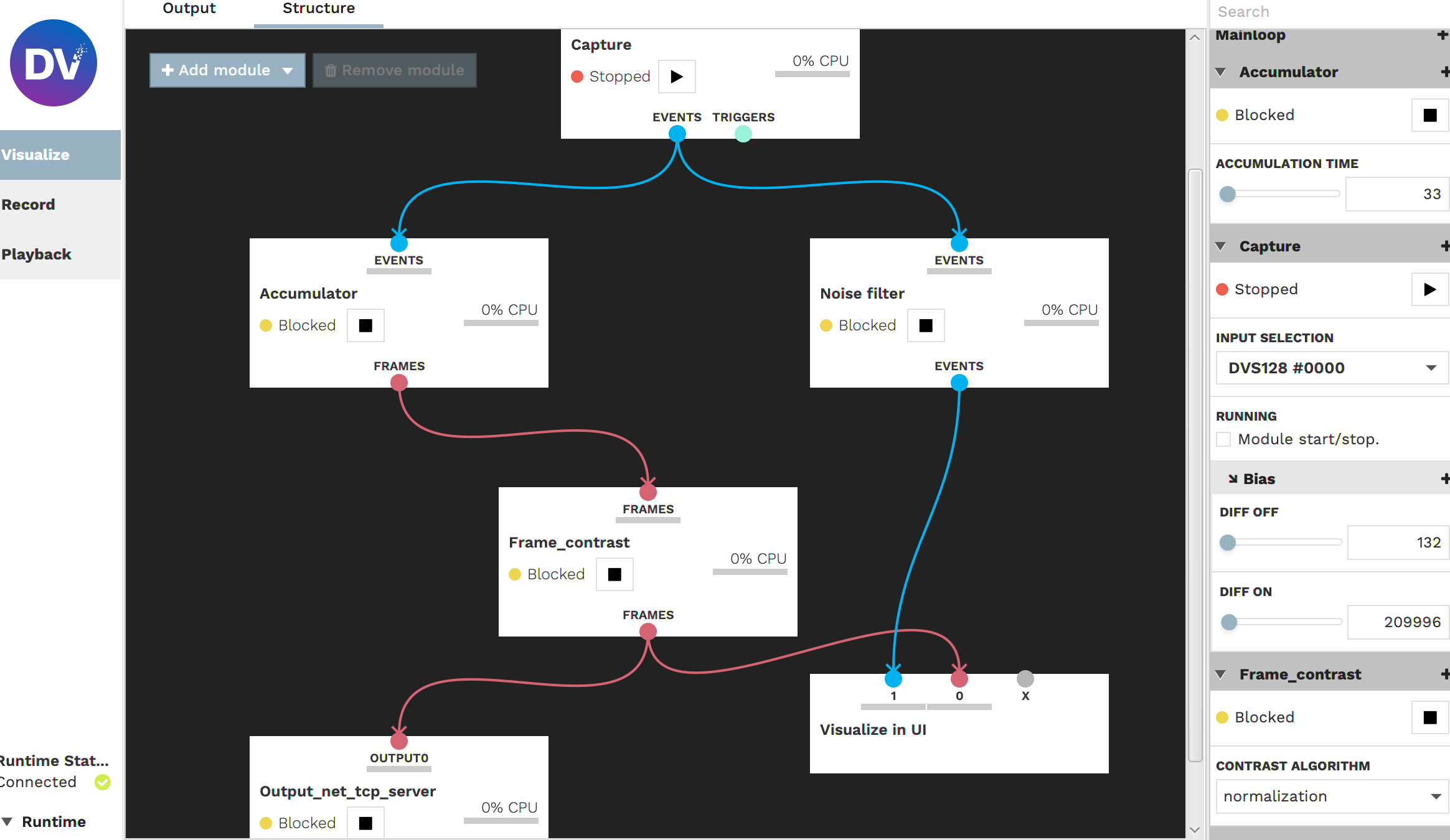
The project addresses the problem of monocular depth extraction in a comparative setup between traditional (frame-based) cameras and novel event-based cameras. The core goal of the project is the design and implementation of a test rig, a software framework for benchmarking algorithms, together with their calibration and validation. This first project sets the ground for upcoming research aiming at evaluating which is the best configuration of camera type and algorithm for monocular depth extraction for assistive devices. The test rig developed in the initial project combined a dynamics vision sensor (event-based camera) and a Kinect sensor.
The GUI allows the developer to choose the algorithm, parametrize, calibrate, validate it and load/save data.
The benchmark framework data ingestion, processing, and evaluation pipeline overview.

VIRTOOAIR
VIrtual Reality TOOlbox for Avatar Intelligent Reconstruction
Concept
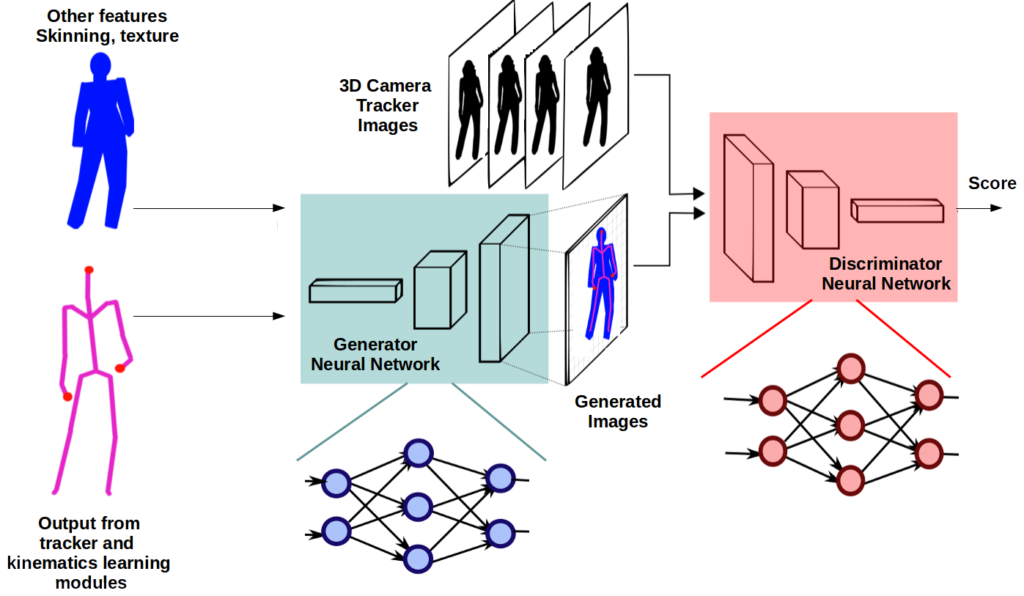
The project focuses on designing and developing a Deep Learning framework for improved avatar representations in immersive collaborative virtual environments. The proposed infrastructure is built on a modular architecture tackling: a) a predictive avatar tracking module; b) an inverse kinematic learning module; c) an efficient data representation and compression module.
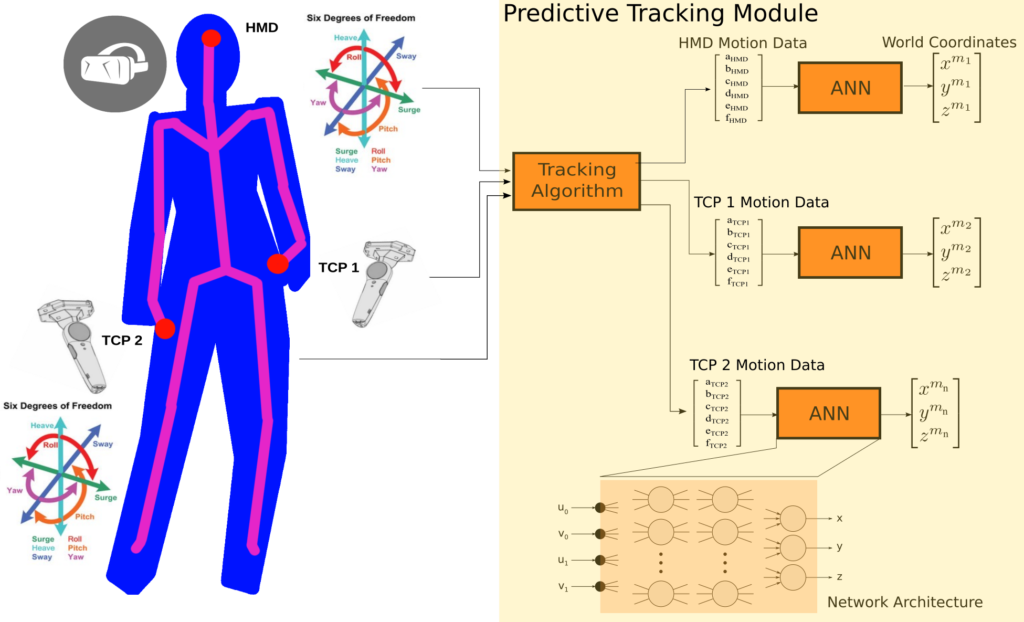
In order to perform precise predictive tracking of the body without using a camera motion capture system we need proper calibration data of the 18 degrees-of-freedom provided by the VR devices, namely the HMD and the two hand controllers. Such a calibration procedure involves the mathematical modelling of a complex geometrical setup. As a first component of VIRTOOAIR we propose a novel position calibration method using deep artificial neural networks, as depicted in the next figure.
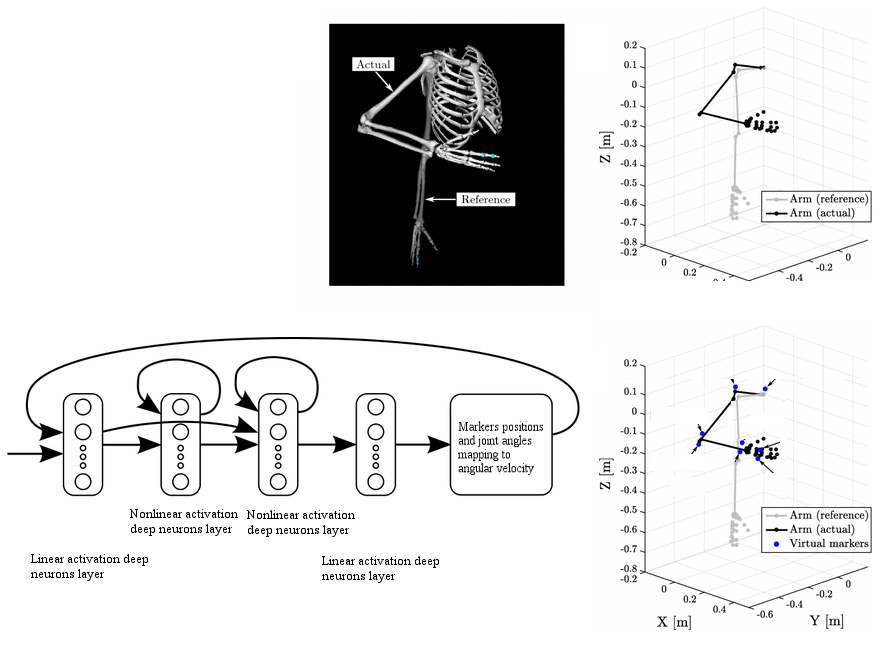
The second component in the VIRTOOAIR toolbox is the inverse kinematics learner, generically described in the following diagram. The problem of learning of inverse kinematics in VR avatars interactions is useful when the kinematics of the head, body or controllers are not accurately available, when Cartesian information is not available from camera coordinates, or when the computation complexity of analytical solutions becomes too high.
Data and bandwidth constraints are substantial in remote VR environments. However, such problems can be solved through compression techniques and network topologies advances. VIRTOOAIR proposes to tackle this problem through its third component, a neural network data representation (compression and reconstruction) module, described in the following diagram.
The project aims at integrating such systems in various technical applications targeting the biomedical field, for rehabilitation and remote assistance.
Preliminary results
VR motion reconstruction based on a VR tracking system and a single RGB camera
Our preliminary results demonstrate the advantages of our system’s avatar pose reconstruction. This is mainly determined by the use of a powerful learning system, which offers significantly better results than existing heuristic solutions for inverse kinematics. Our system supports the paradigm shift towards learning systems capable to track full-body avatars inside Virtual Reality without the need of expensive external tracking hardware. The following figure shows preliminary results of our proposed reconstruction system.
VIRTOOAIR Visualization
For the upper body reconstruction, the semantically higher VR tracking system data is used. The lower body parts are reconstructed using state-of-the-art deep learning mechanism which allows pose recovery in an end-to-end manner. The system can be split in five different parts: tracking data acquisition, inverse kinematic regression, image processing, end-to-end recovery and visualization.

VIRTOOAIR Architecture
First test results with the described system show that it is capable to recovery human motion inside Virtual Reality and outperforms existing Inverse Kinematic solvers for the upper body joint configuration. The following table shows the mean per joint position error (MPJPE) and the mean per joint rotation error (MPJRE):
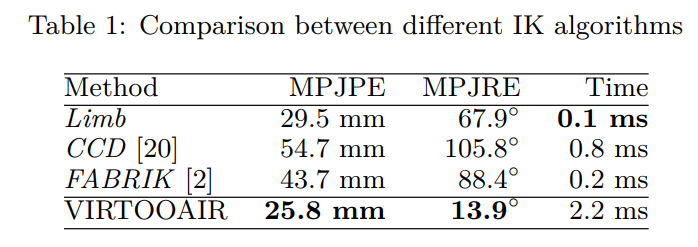
VIRTOOAIR Preliminary evaluation
With the proposed system we introduced a novel, inexpensive approach to achieve high-fidelity multimodal motion capturing and avatar representation in VR. By fusing an inverse kinematics learning module for precise upper-body motion reconstruction, with single RGB camera input for lower-body estimation the system obtains a rich representation of human motion inside VR. The learning capabilities allow natural pose regression with cheap and affordable marker-less motion capturing hardware. In the future we will further extend VIRTOOAIR and combine the gained knowledge about learned IK for upper body reconstruction with the lower-body end-to-end recovery framework for a holistic motion reconstruction framework which fuses the higher semantic VR tracking data with the RGB image stream. Our first results show that deep learning has major advantages compared to traditional computer graphic techniques for avatar reconstruction. Based on our first successes in learning the Inverse Kinematics (IK) with a neural network we will further extend VIRTOOAIR to a holistic system which fuses the RGB camera stream with the precise tracking data of the VR tracking system. One of the challenges is that a huge amount of training data is required. Available motion databases are limited in the sense as that: only a small number of people are captured, the shape of people is not measured and none of the users wears a head mounted display (HMD). To tackle these limitations we will use a game engine based data generator and train a neural network with artificially created images. With this technique we expect that a neural network for human pose and shape tracking can be trained without the need of very costly motion capturing systems and a huge amount of users preforming different motions.
VR motion tracking and prediction based on a VR tracking system and deep recurrent neural networks (RNN)
Our initial studies shown that Motion Capturing Systems suffer from several problems, such as latencies between body-movements and the calculations of the changed position or loss of the optical contact of the tracking system and the tracking devices. To tackle these problems we designed a neural tracking network system. This system uses LSTM (Long-Short Term Memory) Cells to predict the future position and rotation of the tracking devices based on previous data-points. As LSTMs are capable of memorizing, forgetting and ignoring input over time values, they are a powerful tool to handle time sequences with dynamic length and long-term dependencies, as human motions are.VIRTOOAIR Prediction and Tracking Net Currently this predictive tracking system is capable of predicting the next position of the device within a mean error of 1.3 cm (see blue trace). As metric to evaluate the network, the euclidean distance, e.g. the distance in the three dimensional space between prediction and ground truth, is used. For a multi-step prediction a recursive approach is used. Here the prediction of the network itself is used as the next input (see green trace). The assumption, that the prediction of the further movement path is done by the feedback-loop, is insufficient as it assumes a limited order of time-lags fed into the network while training it. With a poor chosen order of time-lags, there may not be enough information of the past to predict far ahead into the future, as the order of Truncated Back-propagation Through Time (i.e. TBPTT - training approach for the LSTM) is correlated with the order of time-lags. Using a too small order of the TBPTT means that the error is not propagated far enough into the past and this induces a problem in network's learning process for the long-term-dependencies. In this case the error back-propagation stops before reaching the horizon and thus makes it unfeasible to do long-term predictions.
VIRTOOAIR Prediction and Tracking Performance
NEURAEV
Event-based Neuromorphic VISion for Autonomous Electic Vehicles
Scope
The current research project aims at exploring object detection algorithms using a novel neuromorphic vision sensor with deep learning neural networks for autonomous electric cars. More precisely, this work will be conducted with the Schanzer Racing Electric (SRE) team at the Technical University of Ingolstadt. SRE is a team of around 80 students, that design, develop and manufacture an all-electric racing car every year to compete in Formula Student Electric. The use of neuromorphic vision sensors together with deep neural networks for object detection is the innovation that the project proposes.We gratefully acknowledge the support of NVIDIA Corporation with the donation of the Titan Xp GPU used for this research.Context
Autonomous driving is a highly discussed topic, but in order to operate autonomously, the car needs to sense its environment. Vision provides the most informative and structured modality capable of grounding perception in autonomous vehicles. In the last decades, classical computer vision algorithms were used to not only locate relevant objects in the scene, but also to classify them. But in recent years, major improvements were reached when first deep learning object detectors were developed. In general, such object detectors use a convolutional feature extractor as their basis. Due to the multitude of feature extraction algorithms, there are numerous combinations of feature extractor and object detectors, which influences a system designer’s approach. One of the most interesting niches is the analysis of traffic scenarios. Such scenarios require fast computation of features and classification for decision making. Our approach to object detection, recognition and decision making aims at “going away from frames”. Instead of using traditional RGB cameras we aim at utilizing dynamic vision sensors (DVS - https://inivation.com/dvs/). Dynamic vision sensors mimic basic characteristics of human visual processing (i.e. neuromorphic vision) and have created a new paradigm in vision research. Similar to photoreceptors in the human retina, a single DVS pixel (receptor) can generate events in response to a change of detected illumination. Events encode dynamic features of the scene, e.g. moving objects, using a spatio-temporal set of events. Since DVS sensors drastically reduce redundant pixels (e.g. static background features) and encode objects in a frame-less fashion with high temporal resolution (about 1 μs), it is well suited for fast motion analyses and tracking. DVS are capable of operating in uncontrolled environments with varying lighting conditions because of their high dynamic range of operation (120 dB). As traffic situations yield fast detection and precise estimation, we plan to use such an event-based visual representation together with two convolutional networks proved to be suitable for the task. The two algorithms we plan to explore are the Single Shot Multibox Detector (SSMD), which got popular for its fast computation speed, and the Faster Region-Based Convolutional Neural Network (Faster RCNN), which is known to be a slow but performant detector.Motivation
The project tries to set a fundamental exploratory work, both in terms of sensory data for environment perception and also neural network architectures for the considered task. The experiments aim at evaluating also the points where better accuracy can only be obtained by sacrificing computation time. The two architecture we chose are opposite. The first one is the SSMD network with Inception V2 as a feature extractor. This network has a low computation time with acceptable accuracy. The correspondent network is the Faster RCNN with ResNet-101 as its feature extractor. Its accuracy is one of the highest, whereas the computation time is relatively slow. Whereas features are common for frame-based computer vision problems, no solution exists yet to determine unique features in event streams. This is the first step towards more complex algorithms operating on the sparse event-stream. The possibility to create unique filter responses gives rise to the notion of temporal features. This opens the exploratory work we envision in this project, to investigate the use of SSMD and Faster RCNN networks using event-based input in a natively parallel processing pipeline.Current state (November 2018)
Progress overview In the progress of developing deep neural network structures (i.e. the SSMD and Faster RCNN) that operate on the event based features to deal with the stereo problem the team investigated first how to represent the event-based visual information to be fed to the deep neural networks. The team developed a series of neural networks for object detection of the lane markings. Not only the networks could identify the type of object (object classification), but more importantly gain real-time data about the localization of the given object itself (object localization). By collecting and labeling a large training dataset of objects, the team implemented various neuronal networks providing us the needed accuracy for safely maneuvering our car. The networks used pre-trained weights from an already existing network for speeding up the training process significantly. The employed methods tapped into transfer learning, before nVidia actually releasing the Transfer Learning Toolkit. The team employed pre-trained deep learning models such as ResNet-10, ResNet-18, ResNet-50, GoogLeNet, VGG-16 and VGG-19 as a basis for adapting to their custom dataset. These networks could incrementally retrain the model with the help of the Transfer Learning for both object detection and image classification use cases. The TitanX GPU granted through the Nvidia GPU Grant program allowed the team to train the deep networks. Development stages In the first development phases, the team used nVidia’s Drivenet without modification. The input size with 1248 to 384 pixels was found suitable for our application. A screenshot with this image size used for training can be seen in the following.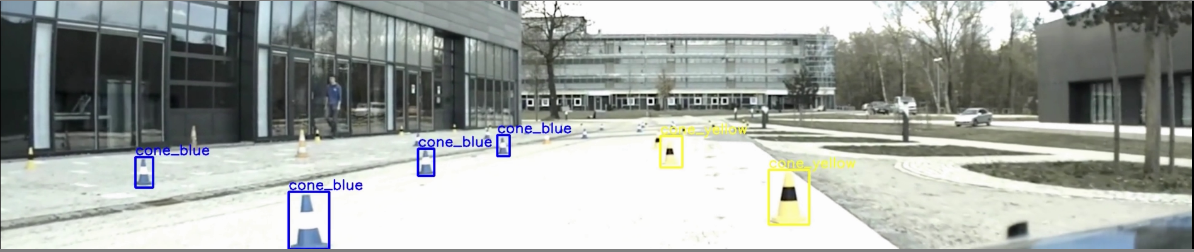 The team was further able to optimize the network input size for the autonomous electric car application by adjusting the first layers of the Detectnet architecture and thus using the whole camera image width of 1900 pixels. While this step lowered the computational performance of inference at first, the team made great improvements in detection speed using a TensorRT optimized version of the net. The comparison of different network architectures vs. their computational performance can be seen in the following. Measurements were taken on a Nvidia Drive PX2 platform.
The team was further able to optimize the network input size for the autonomous electric car application by adjusting the first layers of the Detectnet architecture and thus using the whole camera image width of 1900 pixels. While this step lowered the computational performance of inference at first, the team made great improvements in detection speed using a TensorRT optimized version of the net. The comparison of different network architectures vs. their computational performance can be seen in the following. Measurements were taken on a Nvidia Drive PX2 platform. 
Using the predicted bounding boxes of this network, the Nvidia Driveworks API and a triangulation based localization approach, the team was able to predict 2D position of the road markings with +- 5% accuracy. To further increase the system’s debugging possibilities and gain experience with different neural network models, the team took a darknet approach into consideration. More precisely, the team made experiments with yoloV3 as well as tiny yoloV3, which allowed for an easy implementation into the existing ROS environment. Yolo allows straightforward adaptation of network architecture. Furthermore, varying input image sizes can be used without the need to retrain the whole network, which makes it very flexible for ongoing development. The used yoloV3 network architecture is shown in the following diagram.

Yolo utilizes the great power of CUDA and CUDNN to speed up training and inference, but is also highly portable to various systems using GPU or CPU resources. Again, the team is very thankful given the TitanX GPU which allowed us to execute the network training and inference testing. The team is currently experimenting with the amount and design of convolution and pooling layers. As the objects to detect are rather simple, it should be sufficient to use a small amount of convolutional filters opposing to the original yolonet architecture. Wile the original yoloV3 uses 173.588 Bflops per network execution, reducing the amount of layers results in 148.475 respectively 21.883 Bflops per iteration. These networks are not fully trained yet, but promise to deliver satisfying accuracy with much less inference time. Next steps In the next steps, having classification and recognition tackled, the team will focus on designing a network architecture able to take into account temporal aspects of the stereo-events from the neuromorphic camera in addition to existing physical constraints such as cross-disparity uniqueness and within-disparity smoothness. The network’s input includes the retinal location of a single event (pixel coordinates) and the time at which it has been detected. Consequently such non-linear processing, with good inference timing, offered by the yoloV3 and Detectnet can further facilitate a mechanism to extract a global spatio-temporal correlation for input events. Knowing the disparity of a moving object in the car’s vision sensors’ field of view, the team will further analyse the accuracy and the detection rate of the proposed algorithm.
Preliminary results ( July 2018)
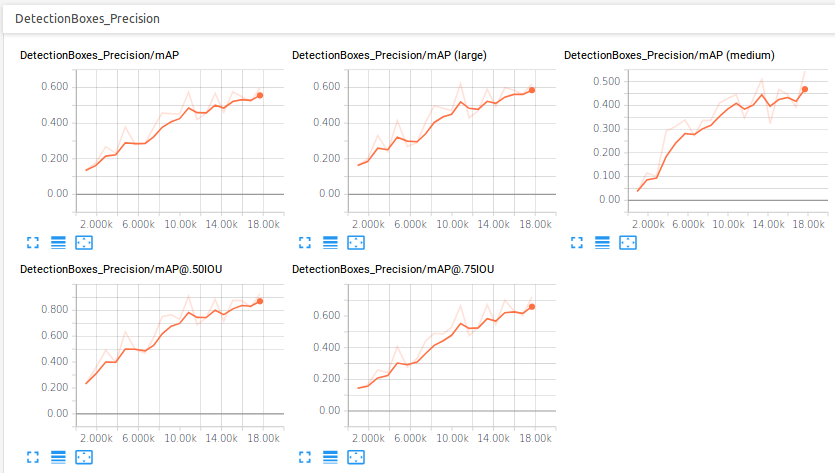
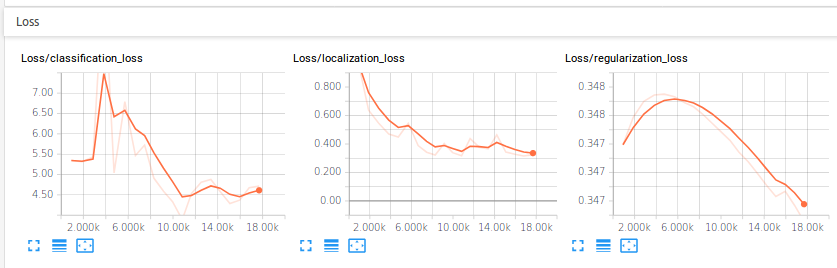
The initial step was carried in training a single shot detector (mobilenet) for the cone detection, a stage in the preparation the Formula Electric competition. Experiments were carried on an nVidia GTX1080Ti GPU using TensorRT. The performance evaluation is shown in the following diagrams.


STREAMING
Online Distributed Machine Learning on Streams
Streams are sequences of events (i.e. tuples containing various types of data) that are generated by various sources (e.g. sensors, machines or humans) in a chronologically ordered fashion. The stream processing paradigm involves applying business functions over the events in the stream. A typical approach to stream processing assumes accumulating such events within certain boundaries at a given time and applying functions on the resulting collection. Such transient event collections are termed windows. Stream processing paradigm simplifies parallel software and hardware by restricting the parallel computation that can be performed. Given a sequence of data (a stream), a series of operations (functions) is applied to each element in the stream, in a declarative way, we specify what we want to achieve and not how. Big Data Stream Online Learning is more challenging than batch or offline learning, since the data may not preserve the same distribution over the lifetime of the stream. Moreover, each example coming in a stream can only be processed once, or needs to be summarized with a small memory footprint, and the learning algorithms must be efficient. 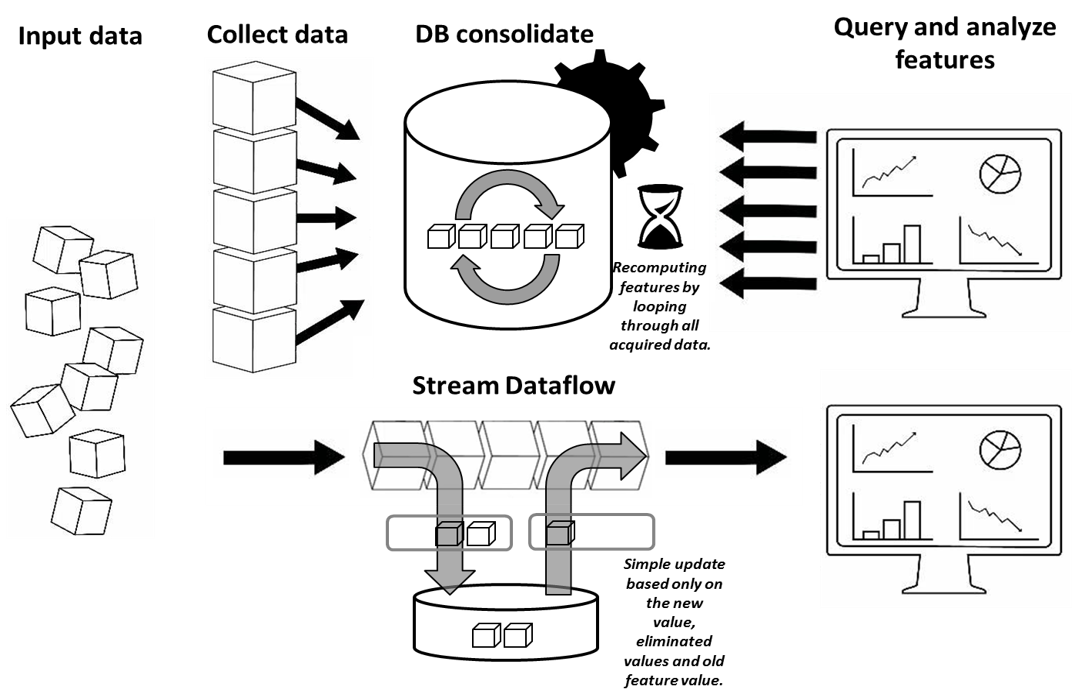
The need for Online Machine Learning - How to compute the entropy of a collection of infinite data, where the domain of the variables can be huge and the number of classes of objects is not known a priori?
- How to maintain the k-most frequent items in a retail data warehouse with 3 TB of data, 100s of GB of new sales records updated daily with 1000000s different items?
- What becomes of statistical computations when the learner can only afford one pass through each data sample because of time and memory constraints; when the learner has to decide on-the-fly what is relevant and process it and what is redundant and could be discarded?
This project focuses on developing new Online Machine Learning algorithms that run distributedly on clusters using a stream processor. The characteristics of the streaming data entail a new vision due to the fact that:
- Data are made available through unlimited streams that continuously flow, eventually at high speed, over time;
- The underlying regularities may evolve over time rather than being stationary;
- The data can no longer be considered as independent and identically distributed;
- The data are now often spatially as well as time situated.
Streaming PCA 






NEUROBOTICS
Adaptive Neuromorphic Sensorimotor Control for Robotics and Autonomous Systems
Efficient sensorimotor processing is inherently driven by physical real-world constraints that an acting agent faces in its environment. Sensory streams contain certain statistical dependencies determined by the structure of the world, which impose constraints on a system’s sensorimotor affordances. This limits the number of possible sensory information patterns and plausible motor actions. Learning mechanisms allow the system to extract the underlying correlations in sensorimotor streams. This research direction focused on the exploration of sensorimotor learning paradigms for embedding adaptive behaviors in robotic system and demonstrate flexible control systems using neuromorphic hardware and neural-based adaptive control. I employed large-scale neural networks for gathering and processing complex sensory information, learning sensorimotor contingencies, and providing adaptive responses. To investigate the properties of such systems, I developed flexible embodied robot platforms and integrate them within a rich tool suite for specifying neural algorithms that can be implemented in embedded neuromorphic hardware. 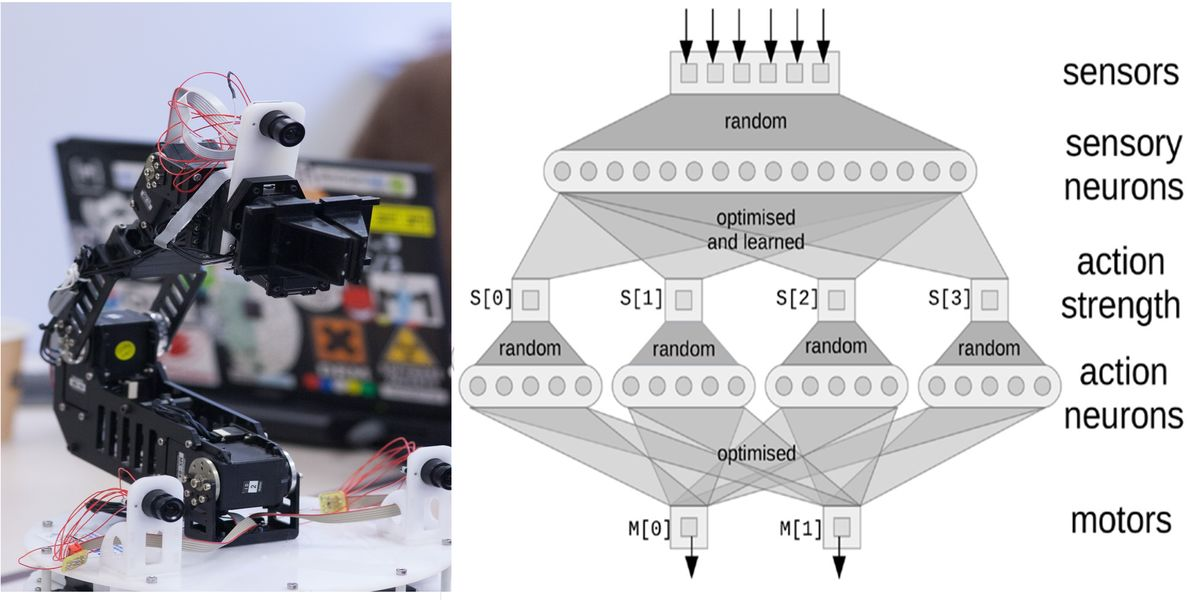
The mobile manipulator I developed at NST for adaptive sensorimotor systems consists of an omni-directional (holonomic) mobile manipulation platform with embedded low-level motor control and multimodal sensors. The on-board micro-controller receives desired commands via WiFi and continuously adapts the platform's velocity controller. The robot’s integrated sensors include wheel encoders for estimating odometry, a 9DoF inertial measurement unit, a proximity bump-sensor ring and three event-based embedded dynamic vision sensors (eDVS) for visual input. 
The mobile platform carries an optional 6 axis robotic arm with a reach of >40cm. This robotic arm is composed of a set of links connected together by revolute joints and allows lifting objects of up to 800 grams. The mobile platform contains an on-board battery of 360 Wh, which allows autonomous operation for well above 5h.
SENSSYS
Synthesis of Distributed Cognitive Systems - Learning and Development of Multisensory Integration
This research direction is looking at developing sensor fusion mechanisms for robotic applications. In order to extend the interacting areas framework a second direction in my research focuses on learning and development mechanisms. Human perception improves through exposure to the environment. A wealth of sensory streams which provide a rich experience continuously refine the internal representations of the environment and own state. Furthermore, these representations determine more precise motor planning. An essential component in motor planning and navigation, in both real and artificial systems, is egomotion estimation. Given the multimodal nature of the sensory cues, learning crossmodal correlations improves the precision and flexibility of motion estimates. During development, the biological nervous system must constantly combine various sources of information and moreover track and anticipate changes in one or more of the cues. Furthermore, the adaptive development of the functional organisation of the cortical areas seems to depend strongly on the available sensory inputs, which gradually sharpen their response, given the constraints imposed by the cross-sensory relations. Learning processes which take place during the development of a biological nervous system enable it to extract mappings between external stimuli and its internal state. Precise egomotion estimation is essential to keep these external and internal cues coherent given the rich multisensory environment. In this work we present a learning model which, given various sensory inputs, converges to a state providing a coherent representation of the sensory space and the cross-sensory relations.
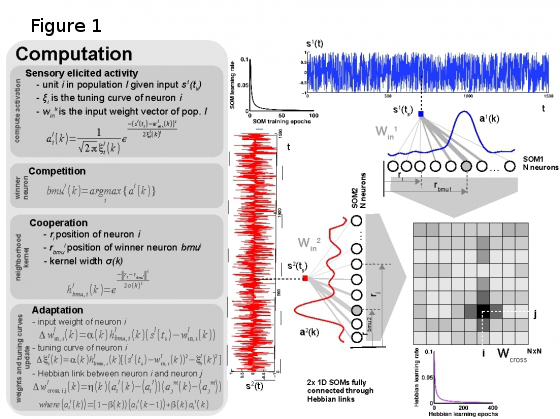
The model is based on Self-Organizing-Maps and Hebbian learning (see Figure 1) using sparse population coded representations of sensory data. The SOM is used to represent the sensory data, while the Hebbian linkage extracts the coactivation pattern given the input modalitites eliciting peaks of activity in the neural populations. The model was able to learn the intrinsic sensory data statistics without any prior knowledge (see Figure 2).
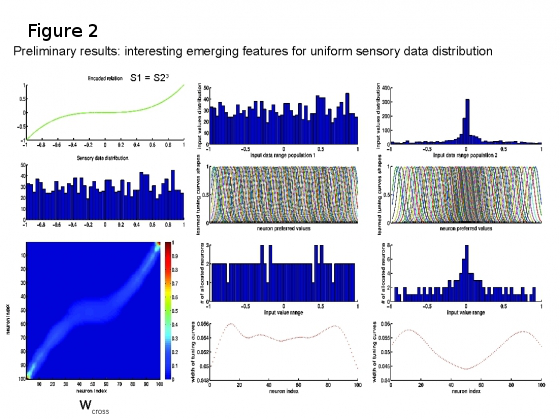
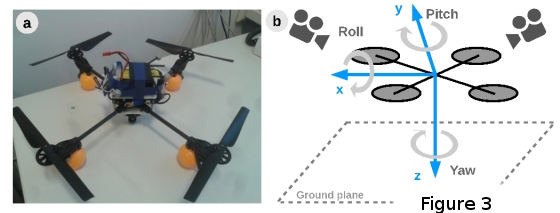
The developed model, implemented for 3D egomotion estimation on a quadrotor, provides precise estimates for roll, pitch and yaw angles (setup depicted in Figure 3a, b).
Given relatively complex and multimodal scenarios in which robotic systems operate, with noisy and partially observable environment features, the capability to precisely and timely extract estimates of egomotion critically influences the set of possible actions.
Utilising simple and computationally effective mechanisms, the proposed model is able to learn the intrinsic correlational structure of sensory data and provide more precise estimates of egomotion (see Figure 4a, b). 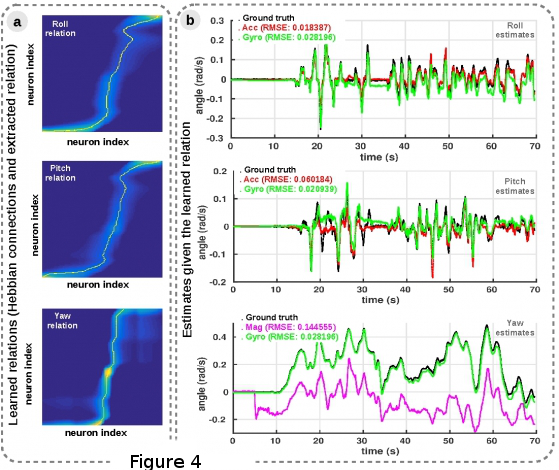
Moreover, by learning the sensory data statistics and distribution, the model is able to judiciously allocate resources for efficient representation and computation without any prior assumptions and simplifications. Alleviating the need for tedious design and parametrisation, it provides a flexible and robust approach to multisensory fusion, making it a promising candidate for robotic applications.
INCOMAPS
Synthesis of Distributed Cognitive Systems - Interacting Cortical Maps for Environmental Interpretation
The core focus of my research interest is in developing sensor fusion mechanisms for robotic applications. These mechanisms enable a robot to obtain a consistent and global percept of its environment using available sensors by learning correlations between them in a distributed processing scheme inspired by cortical mechanisms. Environmental interaction is a significant aspect in the life of every physical entity, which allows the updating of its internal state and acquiring new behaviors. Such interaction is performed by repeated iterations of a perception-cognition-action cycle, in which the entity acquires and memorizes relevant information from the noisily and partially observable environment, to develop a set of applicable behaviors (see Figure 5). 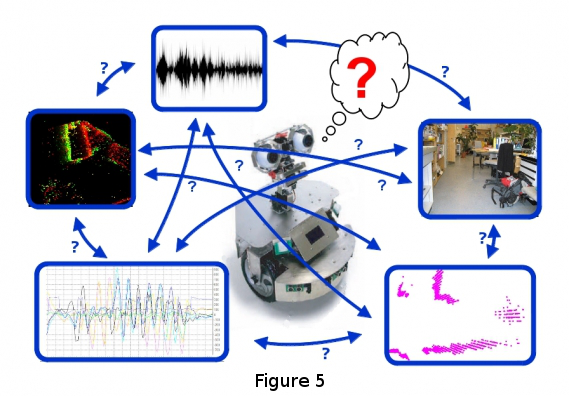
This recently started research project is in the area of mobile robotics; and more specifically in explicit methods applicable for acquiring and maintaining such environmental representations. State-of-the-art implementations build upon probabilistic reasoning algorithms, which typically aim at optimal solutions with the cost of high processing requirements. In this project I am developing an alternative, neurobiologically inspired method for real-time interpretation of sensory stimuli in mobile robotic systems: a distributed networked system with inter-merged information storage and processing that allows efficient parallel reasoning. This networked architecture will be comprised of interconnected heterogeneous software units, each encoding a different feature about the state of the environment that is represented by a local representation (see Figure 6).
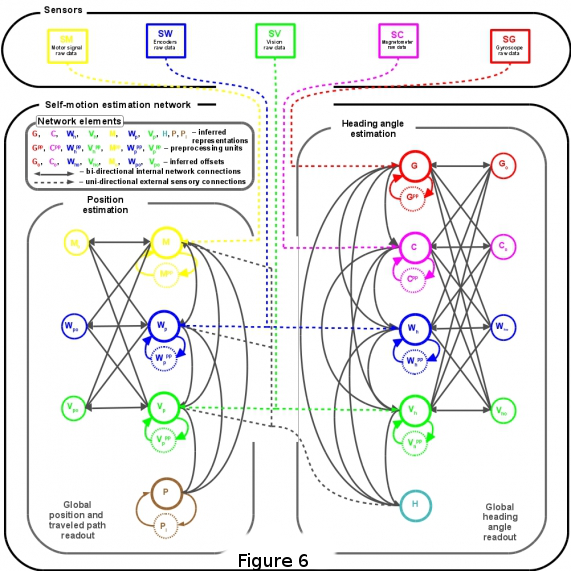
Such extracted pieces of environmental knowledge interact by mutual influence to ensure overall system coherence. A sample instantiation of the developed system focuses on mobile robot heading estimation (see Figure 7). In order to obtain a robust and unambiguous description of robot’s current orientation within its environment inertial, proprioceptive and visual cues are fused (see image). Given available sensory data, the network relaxes to a globally consistent estimate of the robot's heading angle and position.

ARTEMIC
Adaptive Nonlinear Control Algorithm for Fault Tolerant Robot Navigation
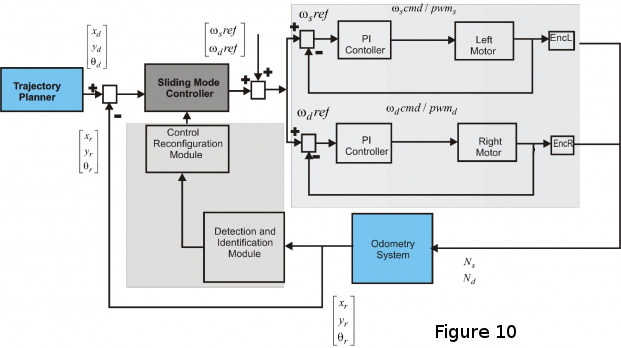
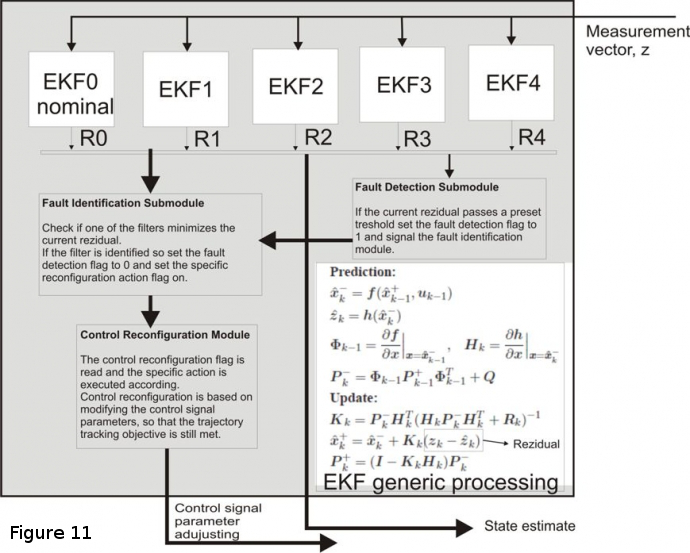
Today’s trends in control engineering and robotics are blending gradually into a slightly challenging area, the development of fault tolerant real-time applications. Hence, applications should timely deliver synchronized data-sets, minimize latency in their response and meet their performance specifications in the presence of disturbances. The fault tolerant behavior in mobile robots refers to the possibility to autonomously detect and identify faults as well as the capability to continue operating after a fault occurred. This work introduces a real-time distributed control application with fault tolerance capabilities for differential wheeled mobile robots (see Figure 8). 
Furthremore, the application was extended to introduce a novel implementation for limited sensor mobile robots environment mapping. The developed algorithm is a SLAM implementation. It uses real time data acquired from the sonar ring and uses this information to feed the mapping module for offline mapping (see Figure 9). 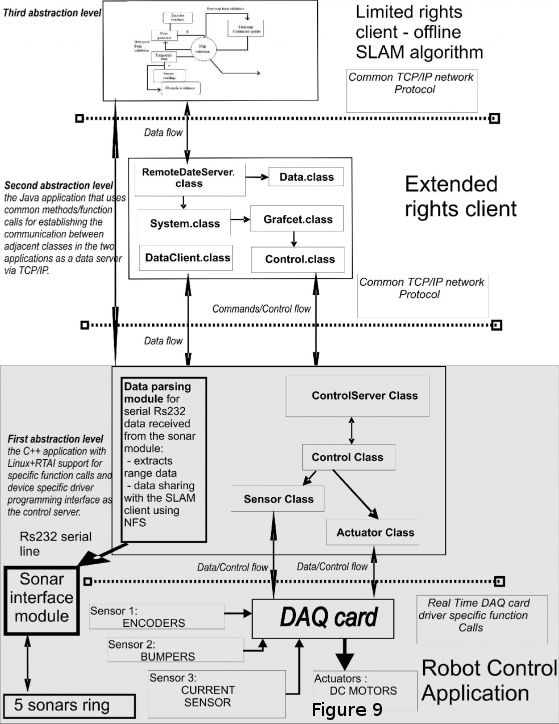
The latter is running on top of the real time fault tolerant control application for mobile robot trajectory tracking operation (see Figures 10, 11).